Ever since organizing Astro Hack Week last year, I’ve been thinking about how to improve our process for selecting participants. Because we knew from the previous year that Astro Hack Week would likely be oversubscribed, for this year’s workshop we were aware that we would have to put some thinking and some effort into how to select participants. This year’s Astro Hack Week is organized by Kyle Barbary, so a lot of what I’m writing below should be attributed to him and conversations we had among the whole group.
It made sense to use our previous automated procedure (updated with a new algorithm and better functionality) implemented in Entrofy (see also previous blog post). In short, Entrofy allows for a selection of a subset of candidates from a larger pool of acceptable applicants based on a set of criteria of relevance.
While the previous blog post was more about the algorithm itself, this will contain more advice on how to use it in practice. Pretty much everything I am saying below can be summarized in a single sentence: think hard about what mix of participants you want to have at your workshop. I still think this is perhaps the most powerful outcome of using Entrofy to select participants. It makes you think very carefully about the design and goals of the workshop and what mix of people will make it successful (and what “successful” means in the first place).
Deciding on Categories
This is by far the most important, and perhaps most fraught, part of the procedure. Which categories should you include in your selection? This depends entirely on your workshop and your goals for it, of course! If you organize a summer school, perhaps the relative number of undergraduate students to graduate students to postdocs is important. If you are organizing a large conference summarizing a whole field, you might want to make sure all subdisciplines are well-represented. If you are like Astro Hack Week, you’ll likely want to know how well people can program, what their previous experiences with statistics and machine learning are, and then mix those. There is no right or wrong answer here. Every workshop is different, so the decisions made here must necessarily be different. That’s okay, as long as you can reason about why you made those decisions.
The single-most important piece of advice I can give here: do this early. As in, long before you even think about opening applications. Everything else below will be informed by the choices you make, and as you’ll see in the next section, once you’ve given people questions, it’s too late.
Phrasing Questions
- Use as few open-ended answers as possible. Entrofy expects either discrete values (numerical or strings), or at least continuous real values. Answers like “Well, I’m still a postdoc, but I’m transitioning to more of a research associate position, and I’m also an adjunct and take graduate level classes” are hard to code. This will both give you untold hours of work, and increases the chance of unconscious biases slipping in
- Phrase questions that require self-evaluation with care. You might want to ask “How well can you program?”, and be tempted to use “beginner”, “intermediate”, “expert” as possible answers. The reason why this is a bad idea is the fact that terms such as “beginner” are very subjective. How someone evaluates their own expertise might depend strongly on their seniority as well as who they think the other participants might be. Choose specific measures like “have read about”, “have used in research”, “have implemented myself” that are likely much better calibrated
- Asking for demographic information is very tricky! This year, we decided to query applicants both about gender and ethnicity/race, and spent a long time thinking about how to do this. No matter what you do, this question must be optional. This then leads to the additional problem of “How do we deal with the applicants who did not answer”? Then the question becomes how fine-grained do you ask? Gender doesn’t lend itself all that well to the requirement in Entrofy for discrete values of some form. With both gender and ethnicity, a fine-grained range of options runs the risk that the numbers for any single category are very low, and one might have to ask how to approach selection in this case. I will say here that we do not have a final, definitive answer for this (I’m not sure there is one). For Astro Hack Week, we chose to ask two optional questions (with thanks to Kelle Cruz for the suggestion): “Do you consider yourself a minority in astronomy in terms of gender identity?” and an equivalent question for ethnic/racial background. This circumvents quite a few problems above, but it also comes with disadvantages. In astronomy, women will generally consider themselves a minority. Because there will likely be more women applying compared to other underrepresented gender identities, and entrofy now considers all of them equal in terms of their chance of being accepted, the subset chosen will be representative of the input data. Perhaps this is what you would want. Perhaps it’s not. Additionally, at the moment, the algorithm considers every attribute separately, without taking into account correlation. That means that at the moment, there is no way to take intersectionality into account, unless the user combines categories before selection. These are issues I’d like to address in the future, and I’d love to hear other suggestions on how to approach them.
- Be aware that any open-ended “other” option with a text field will get “other” answers. They will often require some post-processing (for example, we asked for academic subfield within astronomy, but also got a bunch of applications from people who were outside astronomy, but in methodological fields, who gave diverse answers like “statistics”, “machine learning” etc; we grouped them into a new “methods” category before selection)
You are now ready to collect your data!
Setting Target Fractions
Here’s where the last third of your work begins. Before you can select your participants, you need to tell entrofy hour to select them! You’ve decided on categories, and you have defined options within those. At this stage, you need to make a decision for how many participants you want to fall into each option of each category. For example, as a summer school organizer, you might decide that you want to admit 10% undergraduates, 70% graduate students and 20% postdocs.
My strong advice would be to do this before even looking at the data. Entrofy is supposed to be tie-breaker: given that you are equally happy to admit 100 candidates, what are the 20 that will make the workshop most successful? Of course, the definition of “best” is in itself rather ill-defined. For Astro Hack Week, the answer has always been to maximize diversity of experiences, demographics and academic backgrounds. I’ve encountered the criticism a few times that choosing target fractions without looking at the data set is unfair to those groups that might be undersampled compared to the input set. However, I believe this rests on an incorrect premise: the only way to reproduce the input data set would be to completely select participants at random. I’d wager that nobody does this in practice. Instead, the committee will choose a set of participants they think will make the workshop successful, which has no guarantee whatsoever that the output will be “fair” in any way. The question you want to answer in advance is “What would my ideal workshop look like?”, not “What would my ideal workshop look like conditioned on the applicants I have?”.
In some cases, meeting your targets might just be plain impossible (if you only have 2% faculty members among your candidates, but want 25% of your participants to be faculty members, this might just be impossible to achieve). This will obviously change your initially chosen target distributions. That’s okay. The point I would like to make here is that the earlier you decide on your target fractions, the more of a chance you stand to actually put them into practice. Entrofy’s other goal is accountability, and choosing target fractions early makes you accountable for the reasoning of making certain choices.
Astro Hack Week Fractions
Entrofy’s third goal is transparency. So in the interest of transparency, below are some details of the selection procedure chosen for Astro Hack Week 2016. We didn’t quite manage to not look at the data, which to some extent biases the targets, and some we adjusted for various reasons.
We also pre-selected 11 participants: 4 had been rejected from the previous Astro Hack Week, 7 we selected to act as “seeds”: people with strong previous experience to help with hacking, those we needed to be there for teaching, and some who are likely to lead break-out sessions. We could have not bothered to include these in the sample, but Entrofy allows to put in pre-selected participants for one important purpose: while they will definitely be in the output set, their attributes still count towards the target fractions! In practice, this means that if all our pre-selected participants are senior, white, male faculty members, we probably want to account for that in the rest of the participant set. We then ran the selection for the remaining 39 open slots.
We had eight categories for selection in total (academic seniority, academic area of expertise, machine learning experience, statistics experience, programming experience, previous hack day/unconference experience, gender identity, racial/ethnic identity). Below are examples for two of the categories used for selection. Each plot shows the fraction of applicants in the input set with a certain attribute in that category (blue), the fraction of participants in the selected set (green), and our target fractions in black dashed lines.
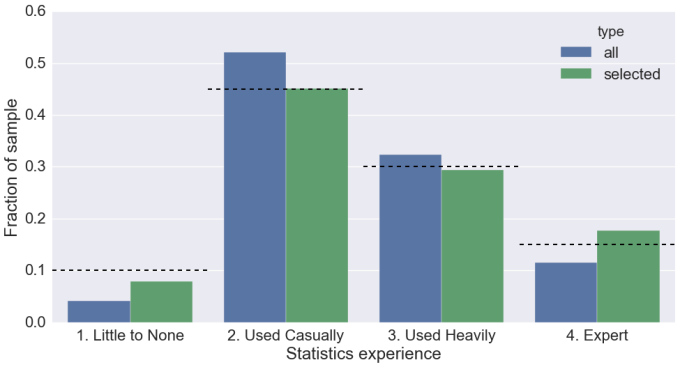
Above is the plot for statistics experience. We decided not to use a flat distribution, because we expected that participants in the second category would probably benefit most from the tutorials at Astro Hack Week, but we also wanted enough experts in the room to achieve a good mixing. You can see how the algorithm tried to move the balance in the set of selected participants close to our targets, but doesn’t manage to do so everywhere. There were simply few applicants who had little to no knowledge in statistics, meaning it was difficult for the algorithm find an optimal set that fulfils that target. For the expert category, the algorithm overshot the target. Remember that the algorithm optimizes the set of participants globally. It is likely that for those participants, the sum of matching the targets in the other categories outweighed the cost of overshooting here.
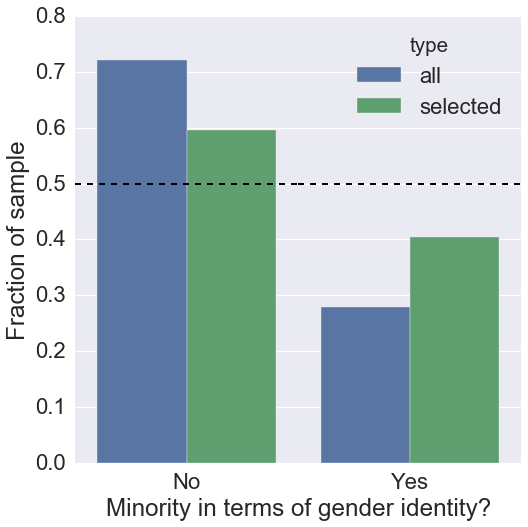
Here is the same plot, but for gender identity. Here, we picked exactly 50/50 as a target. This might be controversial to some, since it does not reproduce the fraction of women in astronomy, which is generally lower. We decided that we are comfortable with this choice for two reasons: first, because we are interested in actively improving representation, and second because we found anecdotally from the year before that having a visible representation of minorities (not only gender) helped with providing an environment where participants felt more comfortable participating. If there are other opinions or suggestions, I would love to hear them here, too.
Post-entrofy procedure
As mentioned above, Entrofy can currently not deal with correlations: it counts every category independently. This is intrinsic in the way the algorithm works, and we can’t really do anything about that unless we change the algorithm a lot. It does have some good plotting capabilities that allow you to plot categories against each other and diagnose strong correlations, or combinations that are missing.
We used this to manually check after selection for correlations between demographics and seniority. We wanted to be sure there was at least one participant who was both senior and and from an underrepresented minority, because we worried that lack of representation and senior role models might increase impostor syndrome in junior members of those underrepresented minorities.
Summary
Astro Hack Week 2015 has taught me a great deal about how to select participants for oversubscribed workshops. This year, we worked hard to learn from my previous mistakes and improve the procedure. I want Astro Hack Week to be diverse and welcoming. Diversity is one of the keys to making Astro Hack Week successful, both in terms of the participants’ academic background and knowledge as well as their demographic background. I am hoping Entrofy can do its part to making the selection more equitable and transparent, and we will continue to work on making it better.

A fascinating look into this area, thanks for summarizing your workings – I’ve shared this with my team who are thinking about planning a hackathon!
LikeLike